Going full send on vibe coding
Earlier this week we were talking about ways to receive one-off dumps of data from customers. For various reasons the customer couldn't use email, and we didn't like the idea of asking them to upload the data into something like a shared google drive folder as that would be adding an additional data subprocessor into the mix.
I've been carefully experimenting with various AI coding agents over the past year. I'm generally skeptical about the ecosystem, but I've been trying to figure out how it might slot into my workflow to either speed me up or improve the quality in some way.
Well, with this problem set I figured I'd take a plung and see what I could produce by going full send on vibe coding. This felt like a pretty perfect project to try this out for two reasons.
- The project is completely independent from any of our other systems. We don't need to think about integrating with a wider platform or anything like that.
- If it doesn't work, we've not really lost anything but a bit of time. There are plenty of other options we could look at after all.
Context
I'm an experienced software engineer, I've been doing this about a decade now. I don't subscribe to the idea that the industry is going to vanish anytime soon just because of LLMs, although I can see it's changing. I think this is important framing to understand why I used the process I did.
Tools
I used the Zed editor, and a combination of Zed's free tier and GitHub Copilot which we have a subscription for.
Process
The approach I took was one of collaboration with the tools, rather than writing some instructions and walking away for an hour. I was actively observing the agent as it ran. Several times I had to tackle something myself which the agent got stuck on. I also stopped the agent mid-run a few times when I saw it going down a path that I knew was going to be optimal or would cause problems.
Project brief, initialisation, and breakdown
I started by scaffolding out a fresh phoenix project and creating a markdown file to house the project brief. I then put together a detailed brief of the project, it was a very messy brief but outlined the functionality we wanted with a rough idea of the UX.
Here's the brief if you're interested.
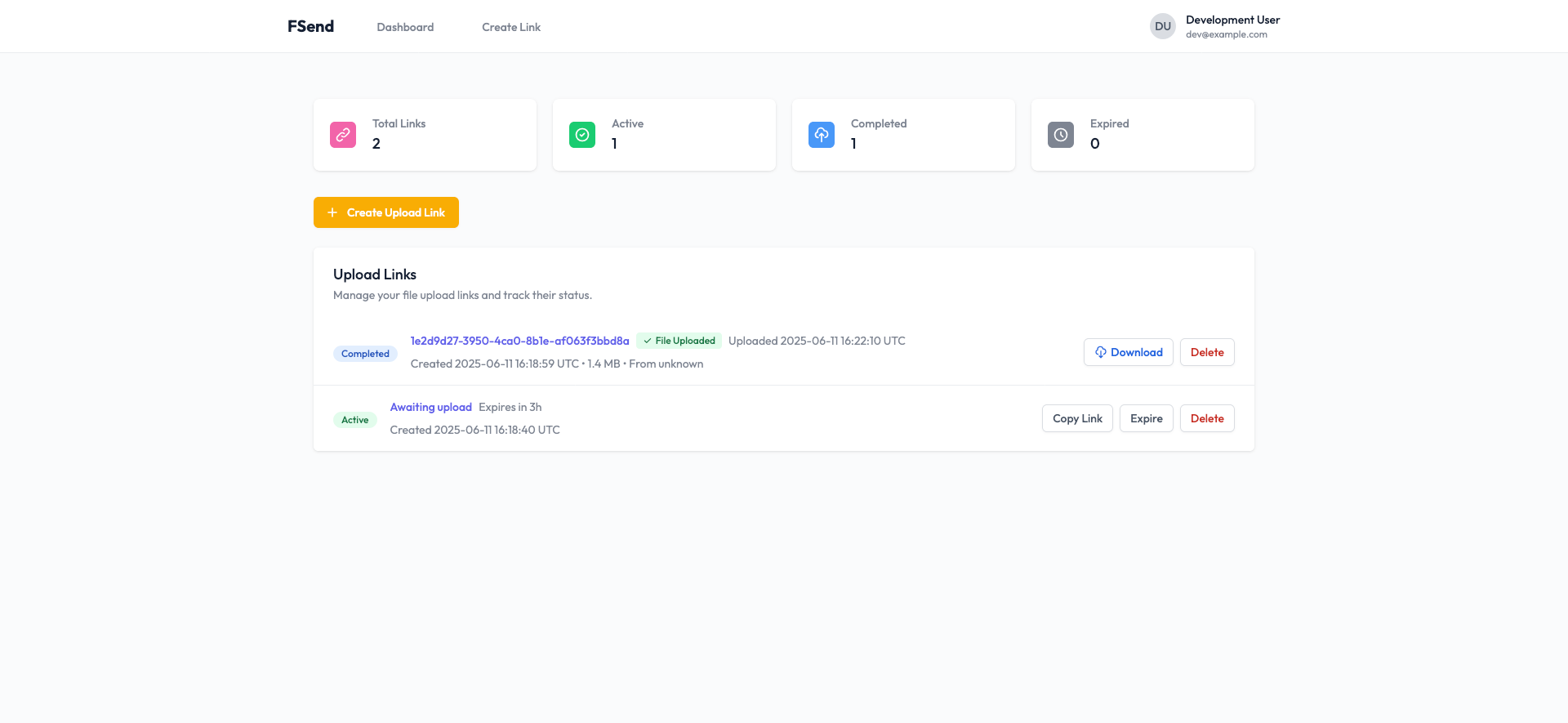
We need a simple web application which allows internal users to generate file upload links. These links can then be shared with external people who can use the link to upload a file or collection of files.
Internal users will be accessing the application over tailscale. Tailscale will attach some headers which can be used to identify the user. We do not need to store user details, we can rely on tailscale to manage this. The headers it will provide are:
* `tailscale-user-login` - This is the users identifier, it'll be similar to an email address. In some cases it will be an email address, ie: [email protected].
* `tailscale-user-name` - This is the users name for display purposes, ie: elliot blackburn
* `tailscale-user-profile-pic` - This is a URL to the users profile picture, this is optional and may not be provided.
Access to the endpoints for internal users will only be possible via tailscale and will otherwise be blocked by a reverse proxy, so you don't need to worry about this. In development mode these headers will not be provided, and we should just set the values to something static to allow easy development.
Internal users will have no identification, and will not require authentication.
When an external user lands on a valid upload page they will be presented with the option to upload a file. The upload should send the content straight into an S3 bucket (when working locally, lets use minio). This can either be streamed, or not - I don't really care right now.
Upload links should have a TTL which can be specified by the external user. The options should be: 1h, 1d, 1w - we may want to change this in the future.
The upload should consist of a single file. If they wish to upload more, they should use a zip. The file type is of no concern to us, we'll allow anything for now.
Once a file has been uploaded, the link should be effectively "closed" in some way.
Links should have the tailscale user login stored against them as the person who generated them. When an upload is completed, the IP and user agent of the person doing the file upload should be logged against the link.
A list of links should be available to all internal users.After creating the brief, I fed it to the model along with a bit of context on the technologies we were using (elixir, postgres, s3/minio, liveview) and asked it to create an implementation plan as a markdown file.
It came up with a structured plan of 6 phases. The early phases had some examples of database schemas and such but beyond that it was very high level. Mostly a list of checkboxes for individual tasks within a phase.
Once we had the brief and the plan, I fed that to a new thread as context and asked it to get going on phase 1.
Development cycle
My cycle after this was pretty similar all the way through. I had it go chug through the tasks and then afterwards I went through and reviewed all of the changes it had made.
At the end of each phase I provided feedback for it and instructed it to make various changes I wanted. These were usually focused on the implementation route it had chosen, or bugs I had found.
Early on I asked it not to write tests and instead did manual testing myself and provided it with feedback. I then went back and had it create tests once I was happy with the implementation approach. This was really just to reduce waste while it was establishing project conventions.
For phase 2 I kept the same conversaion thread going but quickly found the quality start to degrade. It went off on some weird directions, and started rewriting code it had done earlier which I was happy with. After halting it twice and trying to nudget it back on track, I decided to start a new conversation thread.
I carried this forward, creating a new thread for each phase and it seemed to help maintain the focus of the model. It meant it was less likely to run off and start altering code it had put in place in a previous stage unnecessarily.
Places the models struggled
There were two main places the model kept struggling with that caused me to intervene in some way. Most were very benign and quick but there were two which I found more interesting.
The first was the upload screen, this is fairly interactive and uses the phoenix liveview file upload component. This is a little newer than the rest of liveview and not brilliantly documented so I'm not too surprised it struggled. It got around 80% of the way there, I then had to get involved with some manual fixes around the progress tracking. The code it produced caused the upload to stop after only a few chunks had been uploaded, seemingly because it wasn't understanding how to properly update the progress bar and allow the upload to continue.
The second place were the HEEX templates, it seemed to mostly use the old EEX <%= %> syntax when producing html templates. It would still name the files correctly, and HEEX is backwards compatible so it wasn't a huge problem. But my editor was automatically converting the files when the agent saved them. This often caused it to get stuck in a loop of continually trying to "fix" the file as it fought against the editor. I started prompting the LLM to just accept that the editor was correct when it made automatic changes and that seemed to avoid the issue.
Cost
The initial version of the system was created exclusively using the Zed free tier. The tier ran out for me after it was fully usable, but lacking some additional features (like a download button, or cleaning up files when a link was deleted). I then switched to GitHub Copilot which we're already paying for to get it over the line.
So all in all this was mostly free, but of course the free tier won't reset until the start of the month. This has made me strongly consider the Zed pro tier though, which is something I didn't really think I'd care for. Mostly because it supports Claude Sonnet 4, where as Copilot only has 3.7 available. That said, 3.7 wasn't much worse.
Takeaways
Over all, this went very well and we're really happy with the end result. I think the success was due to these primary factors:
- The project was green field, and had no intergration with any of our other systems. The agents didn't need prior knowledge of our business or how we work.
- I'd decided to use a platform with extremely good documentation and strong conventions. I suspect this made the agent much less likely to put code in a weird place. If I had used something like fastapi + sqlalchemy I suspect it would have done okay, but it would have also needed to make it's own decision about code organisation. In phoenix that's not really a problem.
- The scope of the project brief was small enough to fit on a single side of A4. It's arguably one of the simplest applications you could build, with only two external dependencies (postgres and S3 compatible object storage).
- We (myself and the model) chunked up the project, and took it one step at a time. I don't know how well it would have done if I'd had it build the entire thing all at once, but I suspect it would have been much more difficult and required a more involved rescue effort when it got stuck on something.
- I was an active participant, which meant I could bring the agent back on course quickly rather than letting the conversation context get filled up with multiple rounds of trial and error. I feel like this let the threads stay relatively focused which kept it going in a fairly narrow direction forward.
- The agents do an excellent job at building reasonable interfaces with tailwind. I never really mentioned anything around the look and feel and it made something that was generally pretty good. I've made tweaks to it afterwards, but about 90% of the UX was originally from the agent.
I'll definetely give this a go again if I end up with the above set of circumstances. Unfortunately this isn't often the case. I'm interested to see how it would do at building a new system which integrates with one of our internal API's, especially those which have a wide domain with a lot of specific language. My gut says it'll do significantly worse in these cases, but I don't know for sure.
I don't think this will become my primary way of working going forward, but it's extremely cool to see that it's possible. Historically I've been liberal on building small CLI tools for myself, but more reluctant to do web-based ones due to the larger scale of work involved. This could well lower that bar for me to a sufficient degree.
Member discussion